NAMD 2.15 Alpha, AMD HIP/ROCm GPU-accelerated Test Builds
This page contains special developmental early "alpha" test builds of NAMD 2.15 intended to provide very early testing access to the NAMD user and developer communities.
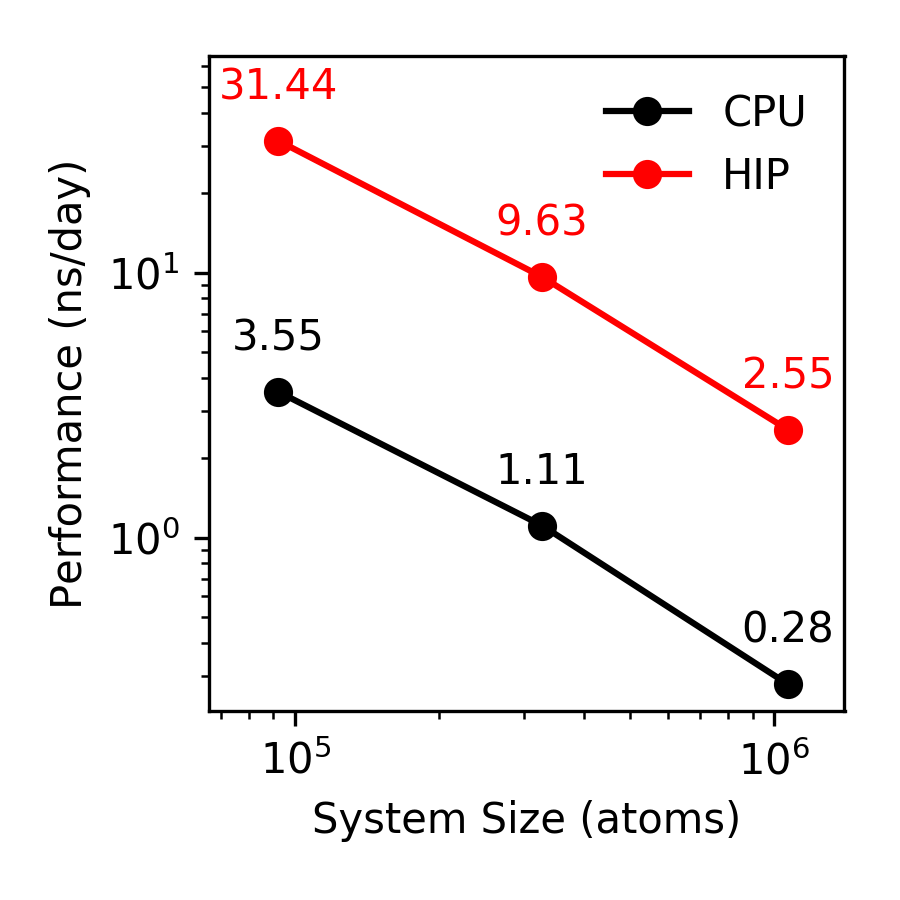
NAMD simulations on the same hardware. Here, we are comparing
three different benchmarks on a single 12-core workstation with
a Radeon Pro VII connected by a PCIe 3.0 interface. Typical
results are that NAMD 2.15 performs 10x faster when it can
engage with the GPU on the node using HIP.
This alpha NAMD 2.15 build for AMD HIP/ROCm GPUs can speed up simulations up to 10 times on Radeon VII PRO when compared with CPU-only simulations using a PCIe 3.X motherboard. Further acceleration is possible on modern Radeon Instinct GPU cards paired with faster CPU-GPU interfaces, such as PCIe 4.X. The alpha also represents the first time that NAMD can utilize AMD GPU hardware to accelerate simulations.
How NAMD uses ROCm
ROCm, and specifically the HIP components that compile CUDA-like code, are used to facilitate the running of NAMD's existing CUDA codepaths with a few minor adjustments.- ROCfft replaces cufft, with slightly different calling signatures
- The nonbonded force and energy calculations use a table lookup rather than reading from texture memory, as that was more performant on older GPU hardware.
What MD Simulations Are Well-Suited to NAMD 2.15 AMD HIP/ROCm Alpha Versions?
The AMD HIP/ROCm builds of NAMD have the same feature set as CUDA builds of NAMD 2.14, as it largely uses the same codepaths. This means that both replica and non-replica equilibrium simulations work well, and functionalities like COLVARS are available. There are no inherent limit to system sizes. However, not all simulations are suitable for these AMD HIP builds, as alchemical simulations, locally enhanced sampling, tabulated energies, pairwise interactions, pressure profile calculations, and QM/MM are not supported.
Due to the way minimization algorithms are implemented in NAMD
(primarily CPU-based) and the way that NAMD performas spatial decomposition
of the molecular system into patches, minimization and dynamics should
be performed in two separate NAMD runs. This ensures that NAMD will
recompute the patch decomposition for dynamics optimally, yielding the
best overall performance for the production part of the simulation.
This code is still evolving and test builds will be updated as needed.
Stay tuned!
For general NAMD information, see the main NAMD home page http://www.ks.uiuc.edu/Research/namd/
For your convenience, NAMD has been ported to and will be installed
on the machines at the NSF-sponsored national supercomputing centers.
If you are planning substantial simulation work of an academic nature
you should apply for these resources. Benchmarks for your proposal
are available at http://www.ks.uiuc.edu/Research/namd/performance.html
The Theoretical and Computational Biophysics Group encourages NAMD users
to be closely involved in the development process through reporting
bugs, contributing fixes, periodical surveys and via other means.
Questions or comments may be directed to namd@ks.uiuc.edu.
We are eager to hear from you, and thank you for using our software!
NAMD 2.15 AMD HIP/ROCm downloads
Compatibility notes
Not all AMD GPUs have the hardware required to run NAMD.
Specifically, ROCm is currently supported only on GFX8 and GFX9 GPUs, and not Navi cards.
NAMD specifically needs hardware that has capabilities first present on gfx803 cards. The pre-compiled binary was compiled for gfx803, gfx900, gfx904, gfx906, and gfx908 compute architectures.
The pre-compiled binary was compiled with ROCm 3.9.0, and includes the dynamic libraries specific to this version of ROCm needed to run NAMD.
With an appropriate library search path, this should allow users to run NAMD without downloading the full ROCm stack immeadiately.
The source files provided can be compiled with ROCm 3.3.0 or newer.
Running NAMD with AMD GPUs
Simulations can be started as usual, with:
namd2 +p 4 configfile.namd
Note that because the codepath follows the CUDA path, the logs reported to standard output as well as GPU-related error messages may contain references to "CUDA" and can lead to confusion. These are hardcoded references within the NAMD code. Users are instructed to realize that the errors should be regarded as their HIP equivalents.
Notes on minimization with NAMD 2.15:
For more information about NAMD and support inquiries:


