The list of tools and capabilities which will be made available to the
users of BioCoRE is extensive and reflects the broad range of modes
in which people work together. To implement the collaboratory
server and components described in Section 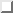 ,
the following strategy will be used:
,
the following strategy will be used:
This strategy will yield collaboratory software that will be familiar in its interface and concepts to both users and new developers. Our goal is to integrate capabilities from a disparate set of applications and tools into a cohesive environment in which structural biologists can work more efficiently.
To support the collaborative user experience detailed in
Sections and ,
BioCoRE sessions must be fast and convenient to join,
clearly beneficial to use, and able to incorporate
many different tools. For this purpose, BioCoRE will have the following
general features and capabilities:
BioCoRE will be implemented using a component approach, which has become a powerful and popular software development method in industry today. The primary components of BioCoRE correspond to the elements of the user interface as discussed in the earlier sections. The basic BioCoRE components are summarized in Figure 2.
All of the BioCoRE components detailed below must communicate with each other and know how to initialize their working environment. For example, the user interfaces, such as Notebook and Workbench must know how to contact the collaboratory server. For these reasons, using a component model requires a standard component architecture and interface mechanism. To match the particular needs of this structural biology collaborative environment, we will first specify a BioCoRE Component Interface (BCI). The BCI will state how BioCoRE components can communicate with other components, find out information about the other components, and exchange data. Each component of BioCoRE such as the Notebook, Workbench, and any new components, will need to implement BCI. Once a component is configured to use the BCI, it will be able to interoperate with any of the other BioCoRE elements. A number of component architectures exist already, such as CORBA ( CORBA, 10 December 1991 ), ActiveX ( Denning, 1997 ), and JavaBeans( Arnold and Gosling, 1998 ; Englander, 1997 ), which can be used to implement the BCI and to provide the network protocol for component communication. JavaBeans is a compelling option for the BCI, since it will make it easy to implement several BioCoRE components as Java applets, servlets, or standalone Java applications in a portable manner.
The Collaboratory Server has been previously mentioned as the point of origin for the user in any BioCoRE collaborative interaction. This server will maintain a database with information about established projects, access control, and active sessions. This server does not need to store all data files related to a project, since BioCoRE will also provide archival data storage components for large, persistent data elements separately.
Users will be provided with a standard web-based interface to connect to the Collaboratory Server the first time they access the BioCoRE environment. Access to the server will be performed through the BCI, and can be implemented with a simple Java applet running in a web browser. Information about available projects and active sessions must be retrieved from the server via the BCI; users must also be able to initiate new projects or sessions. We advocate to use the Lightweight Directory Access Protocol (LDAP) ( Howes and Smith, 1997 ) to access the project and session information, that will naturally follow a directory-like organizational structure.
The collaboratory server will be implemented as a distributed and replicated collection of components to provide fast and reliable access for geographically dispersed users. Since BioCoRE will use the Internet as its backbone, security issues must be addressed by the Collaboratory Server. Techniques such as public key cryptography should be adequate for this purpose. Certificates will be used as a mechanism to identify users to the Collaboratory Server and to join a session.
The Collaboratory Server will only be a repository for the existing collaborative projects. When one or more researchers are actually working at a terminal within the BioCoRE environment, a session will exist. Multiple sessions can exist for a single project, and a user can be associated with more than one session at a time. Each session will have a Session Manager application, that will be responsible for the following tasks: (i) Keeping track of users and projects involved; (ii) Managing connections between user-interface components, data archives, applications active within a session, and collaboraory server.
Most of these activities can be accomplished through the BCI, which must be able to find and communicate with other users' BioCoRE environments. However, management of running applications is complicated for two reasons: (i) the applications may be running in parallel, yet need to link together to share data; (ii) the applications may need to run within specialized computing resources, such as a supercomputer batch queue. Accessing parallel applications as components within technologies such as CORBA ( CORBA, 10 December 1991 ) is not feasible, since CORBA and other popular component architectures do not support the notion of parallel data structures.
To handle the problem of working with parallel applications, the
Session Manager will be implemented using a modified version of the
Parallel Application WorkSpace (PAWS) controller application. PAWS
is a user Application Program Interface (API) and associated
controller process being developed at Los Alamos National Laboratory
as part of the DOE 2000 initiative. It provides a mechanism to allow
two parallel applications, possibly running on different numbers of
processors and possibly using different strategies for parallel data
distribution, to link together to share data.
Using this mechanism, applications such as NAMD or
VMD can be made PAWS components, and can exchange data with any
other PAWS component.
controller application. PAWS
is a user Application Program Interface (API) and associated
controller process being developed at Los Alamos National Laboratory
as part of the DOE 2000 initiative. It provides a mechanism to allow
two parallel applications, possibly running on different numbers of
processors and possibly using different strategies for parallel data
distribution, to link together to share data.
Using this mechanism, applications such as NAMD or
VMD can be made PAWS components, and can exchange data with any
other PAWS component.
Within BioCoRE, we will have an important distinction between two types of components: those implementing the BCI interface, and those implementing the PAWS interface. The Session Manager will act as an overseer for several users to work on a particular project, and as a manager for the applications to be run and linked together. The Session Manager will need to implement both the BCI interface, and the PAWS interface. This will be accomplished by enhancing the existing PAWS controller to include the needed BioCoRE Session Manager capabilities (including a BCI). Resource allocation, scheduling, and user authentication mechanisms will need to be part of BCI and PAWS in order to launch the parallel applications. For this purpose, PAWS is being modified to use the Globus ( Foster and Kesselman, 1998 ) metacomputing infrastructure in order to include compute resource allocation and user authentication support.
A number of components will serve as applications that users run as part of the collaboration, e.g., to visualize simulation results or to compute molecular dynamics trajectories. BioCoRE will incorporate two types of client applications: thin applications and fat applications.
Thin visualization clients will incorporate basic essential
functionalities of popular molecular visualization software such as
VMD and will run as applets
inside a browser window.
Fat clients support the PAWS interface themselves and,
thus, can participate in distributed data sharing with simulation
servers directly.
An important distinction from the implementation point of
view between the thin and fat clients is that the thin clients do not
have BCI integrated within them, but are wrapped by BCI supported by
the Notebook. Fat visualization clients such as VMD,
RASMOL
or Quanta can be launched
and controlled by the Workbench in BioCoRE providing extremely
flexible uses.
Simulation applications, such as NAMD, will also form an important part of the list of fat clients accessible within BioCoRE. Large computations will take place on machines designated as compute (simulation) servers, such as local high-performance workstations or remote supercomputers. The Workbench component of BioCoRE will provide the mechanism for interacting with the job-scheduling protocols on these machines through the use of PAWS controller within the BioCoRE session manager. Needed data files will be automatically retrieved from the collaboratory data archive servers. NAMD will be modified to make use of the PAWS API to participate in distributed data sharing, as will VMD and selected other fat clients. Other simulation programs such as X-PLOR ( Brünger, 1996 ) and CHARMM ( Brooks et al., 1983 ) will be provided with BCI wrappers for incorporation into BioCoRE.
Notebook, Conferences and Workbench are the
primary user interface platforms of BioCoRE. They embed all the other
objects and, thus, act as canvases for visual programming. They
combine the capability to link the related objects to each other
(hypermedia) with extensibility provided through scripts. In
particular, the Notebook is an abstraction for a
domain-specific extensible hypermedia browser. These user interface
components will understand commonly used protocols and interfaces and
will be enriched with applets, plug-ins and scripts to handle
previously unknown types of objects. Notebook will be
implemented as a set of the eXtensible Markup Language (XML) ( Connolly, 1997 ) documents and Java applets
that use JavaBeans as a component model to communicate with each other
within standard web-browsers that support LDAP and Internet Inter-ORB
Protocol (IIOP) ( Orfali and Harkey,
1997 ). An example of electronic notebook software that can be
adapted for the Notebook component is the DOE 2000 Electronic
Notebook project at Oak Ridge
National Laboratory. The Workbench component will provide a
simple visual interface to the PAWS controller capabilities within the
session manager that will control connecting these PAWS clients
together. This will make it possible, e.g, for the collaborating
users, to connect visualization clients to running simulation clients
from different remote sites in user-selectable patterns. Complex data
connection networks will be possible in this environment.
Large data sets will not be stored on the collaboratory servers, but will instead be distributed to a number of archive servers. Although these data sets will be managed and cataloged by the collaboratory servers, they do not need to be replicated except for temporary caching. A wide variety of machines will be capable of acting as archive servers with access methods varying from LDAP or IIOP to remote procedure calls, as determined by a mediating collaboratory server. Databases will be used as a repository of molecular structures and parameters.